A short introduction to Snowflake Storage Concepts

So what is Object Storage anyway?
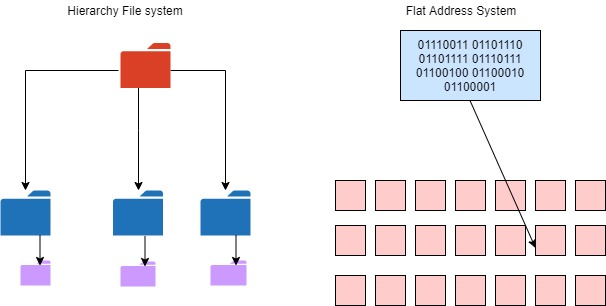
Object Storage is a term for data stored in units of storage called objects. Data is stored in a flat address space also called a storage pool, rather than a directory hierarchical structure we use for o/s files. Object Storage uses an HTTP REST API to access objects.
This flat address space allows:
- Storage to easily scale by adding nodes
- Easily locate files on the storage device
Each Object has 3 attributes
- The Actual Data content
- Metadata to help describe and manage the data, this is customisable as well
- examples: file size, owner, location, create date
- Unique ID address so object can be found without have to know the physical location

How does AWS implement Object Storage?
AWS offering of object storage is called S3 (Simple Storage Solution) lets review some of its concepts
S3 High Availability
The protection of S3 Object Storage can be defined in terms of Durability and Availability
- Durability is the probability a object is accessible after one year (chance of file being lost)
- AWS SLA of 99.99999999999% (11 9s)
- Availability is the probability a object can be retrieved the moment that you ask for it
- Objects are redundantly stored on multiple devices across multiple Availability zones within the region
- AWS guarantees 99.9% Availability
Other attributes of S3 include:
- Unlimited storage scalability due to the flat address space
- Encryption at rest and in transit
- Versioned files, which protects against Deletes, and allows users to rollback to previous version of the file
- Lifecycle Management to control when an object is deleted, or a change in class to a lower cost S3 option
- Object Lock option uses (WORM) and blocks object version deletion for specified time the file is Immutable
- Retention Period to protect object versions for a fixed amount of time, before eligible for delete
Performance
- S3 scales to high request rates, latency 100-200 ms
- Spread reads across different prefixes (flat file name paths) for better performance
- Parallelise GETs by requesting byte range fetch, can use for partial data if needed
Limitations
Object storage generally does not allow the direct editing of parts of a file. A file is accessed, updated and rewritten as a new file.
See: https://docs.aws.amazon.com/AmazonS3/latest/userguide//Welcome.html

How does Snowflake implement Storage?
The Snowflake Storage Layer is built upon the cloud providers Storage platform for Object Storage like Amazon S3. As Snowflake is a Software as a Service (SAAS) offering they will manage all the administration effort with the Cloud Provider, as a customer this administration is all hidden from us.
How does Snowflake store table data on S3?
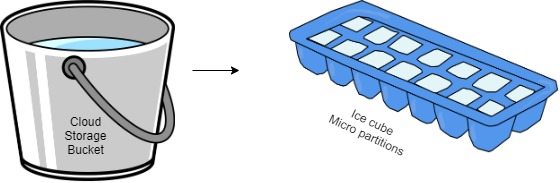
Table data is stored on S3 in units called micro partitions. A Micro Partition is a contiguous unit of Storage that holds data. Each micro partition size will be in the range of 16mb compressed, due to the highly efficient nature of columnar compression this 16Mb of compressed data can equate to upto 500Mb of uncompressed data.
Table Records can not span a micro partition, with many micro partitions making up a table.
The micro partitions are Immutable, not editable, written once they are then read only, any change or update on table implicitly create a new version of micro partition for the tables data that was changed. These versions of the micro partitions are tracked in the services layer
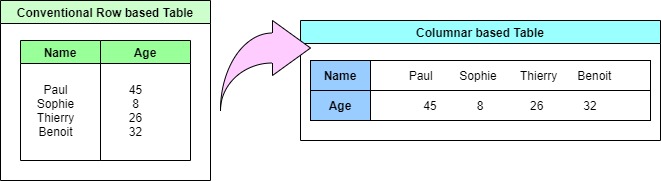
What is columnar data format?
Databases tables conventionally store data in rows, and this is how we conceptualise the data for both querying and DDL, but for large datasets in a warehouse it can make sense to store data in term of columns. Storing similar data together brings huge benefits in terms of very high compression rates and also natural data clustering for querying.
Micro partitions metadata in the Services layer
The Services Layer stores metadata about every micro partition includes
- MIN/MAX (ranges for each column)
- Number of distinct values

This can have huge benefits for us as a user we may not even need to read the actual data on Storage to satisfy a query, the answer may already be part of the metadata in the services layer.
Each version of a micro partition is also tracked in the Services layer, this provides Snowflake capabilities such as
- Time Travel, where historic versions of a micro partition are accessed to query data in the past
- Zero Copy Cloning, where objects can be created referencing existing micro partitions as a starting point
- Fail Safe, With Snowflake admin restore data from an old micro partition nolonger visible to user